Hands-on with Claude Code
The past few months have seen coding assistants really rocket in popularity. GitHib Copilot, Aider and Cursor were popular choices, but now, Anthropic have released their answer in Claude Code. Coupled with the new Sonnet 3.7 model, this has a lot of potential.
In this post, I’m going to walkthrough the build of a new Java REST API from scratch using Claude Code.
TL;DR:
What went well:
- Claude Code is a great coding assistant, and was able to quickly setup (~a couple of hours) a fully functional Java Spring REST API which could perform basic CRUD operations on a MongoDB collection.
- I was able to give it detailed spec of the things that I wanted, and it was able to quickly implement without many issues.
- Project uploaded to GitHub here - github.com/m24murray/hands-on-with-claude-spring-mongo
Concerns:
- I don’t think I could be fully hands-off, there were definitely things I needed to tweak along the way.
- I think it’s great for building an app from scratch, but might be too tricky for working on a larger, more established code base.
- Costs are definitely a concern. I consumed over $10 worth of credits just on this example.
- There’s a potential you can get ‘lost’ along the way. It can be hard to keep track of the changes. In particular, the terminal view for evaluating diffs just doesn’t work on anything over 20/30 loc.
I’ve personally used GitHub Copilot with GPT-4o on projects, and I’m keen to see how this compares.
In this example, I’ll be setting up a standard Java REST API that sits above a database. It’s something that I’ve done many times before, so I should have an idea whether the output is doing the right thing.
Rules
I’ll be trying to setup a functional app from scratch. Claude Code will take a first pass at any of the implementation steps, and then I’ll update manually when needed. I’ll be keeping an eye on costs but not going too out of my way to over-optimise.
Getting started
Installing Claude Code
Claude Code is installed via npm - instructions here.
Once installed and logged in, the tool is run using the claude command.
This returns a different response depending on the contents of the folder the command is executed in. For example, in an
empty folder, Claude will suggest creating a new app. In an existing folder, Claude will analyse the codebase to
determine directory structure, language, framework, build and run instructions. This information is then output to a
file CLAUDE.md which I assume is used as a system prompt for future requests. Users can also manually edit this file
and add information which may be useful to Claude going forward.
In this example, I have an empty directory, so Claude prompts me to create project.
Creating a spec file
So I can type out my instructions within the Claude Code terminal window. However, I think the amount of information I’m going to need to type and then edit might make doing so in a terminal window a bit tricky. Instead, I’m taking some inspiration from the following link on LLM workflows, I’m going to instead construct a spec file that Claude can then read and use as its instructions set.
So outside of Claude (I’m using Chat GPT 4o here), I’ve asked the following prompt:
Hey I want to create a new Java Spring REST API that sits above a mongo db.
Ask me one question at a time so we can develop a detailed spec.
Each question you ask me should build on my previous answers.
Let’s do this iteratively and dig into every relevant detail.
Let me know when you have all the information you need
and then summarise your findings into a file called `spec.md`.
Here’s the details:
* Java Spring REST API project
* Java 21
* Sits on top a mongo db, so will need dependencies pulled in
* We'll work off a basic data model, we'll have a single model called `users`.
* A user will have 3 fields, a unique id, name and email.
* REST API should have controller endpoints for CRUD operations for `users`.
* Standard controller, service, repository structure
* API endpoints should have an Open API spec that i can send to other teams
* Will need unit tests
* Don't worry about security/auth right now, we'll implement that later
* Use gradle for dependency mgmt.
The clarifying questions include things like:
- Custom error handling
- Data validation
- API path and versioning
- Testing frameworks
- Deployment configuration
After about 15 questions, the results are output into a spec file, which can be seen here - spec.md.
It includes sections on tech stack, data model, api endpoints and testing.
I will then give this to Claude and ask it to start implementing.
Implementation
This is my first prompt to Claude Code:
There is a file in this codebase called spec.md
that include a detailed specification for a java spring app that I want to build.
I want you to break it down into small, iterative pieces that you can implement.
Some rules:
* Each iteration of implementation must fit in with what has come before it.
* Implement with TDD to ensure correctness at all times.
* Everything should be cohesive and there should be no orphaned code.
At each stage of the journey I want you to update a file called implementation-instructions.md
with a set of detailed prompts of what you are about to implement.
This is useful for me to have a history of the changes.
Claude has picked up the file, and has established a test of implementation instructions, which can be seen here - implementation-instructions.md.
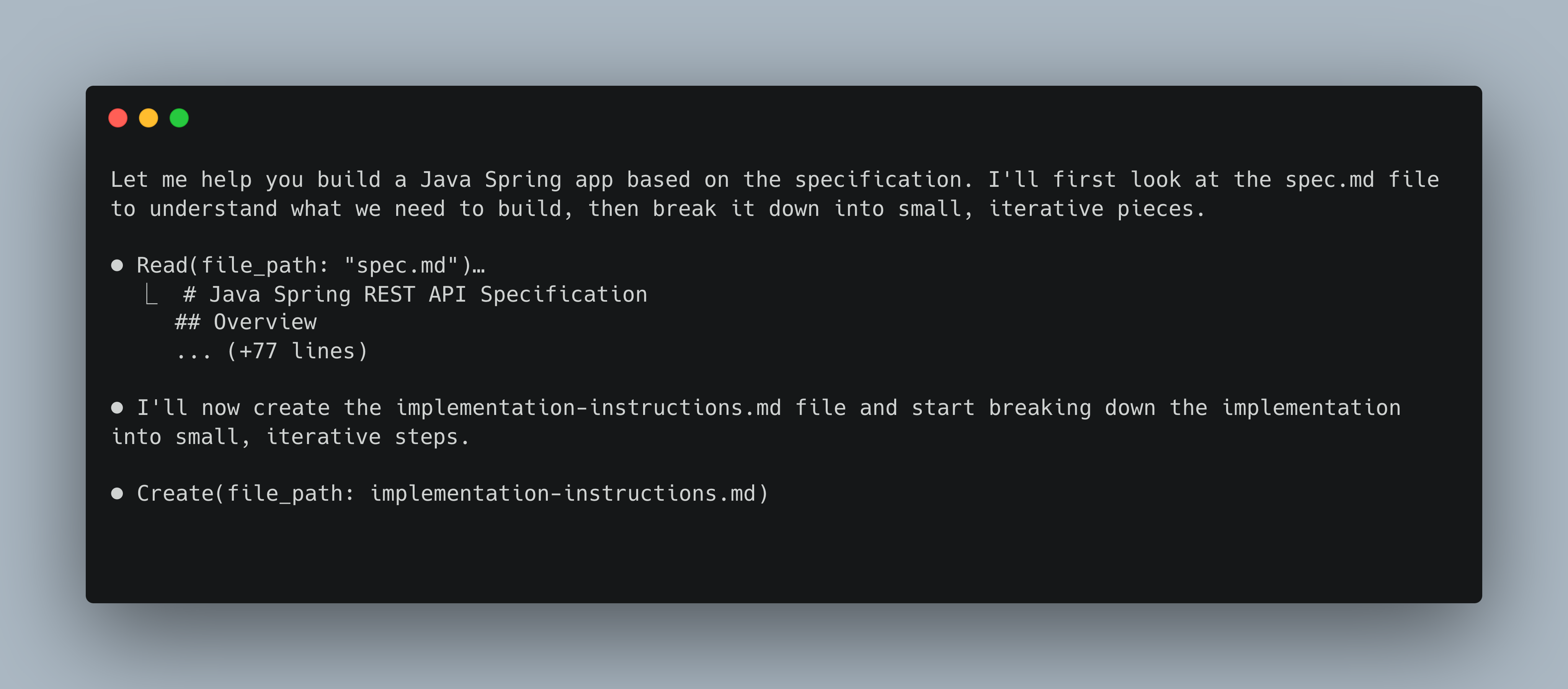
I’ve reviewed the proposed steps, and have asked it to proceed. It has then updated the implementation instructions with more information, so we get an idea of what its about to do next. This will be great for getting a bit of an audit log of the implementation.
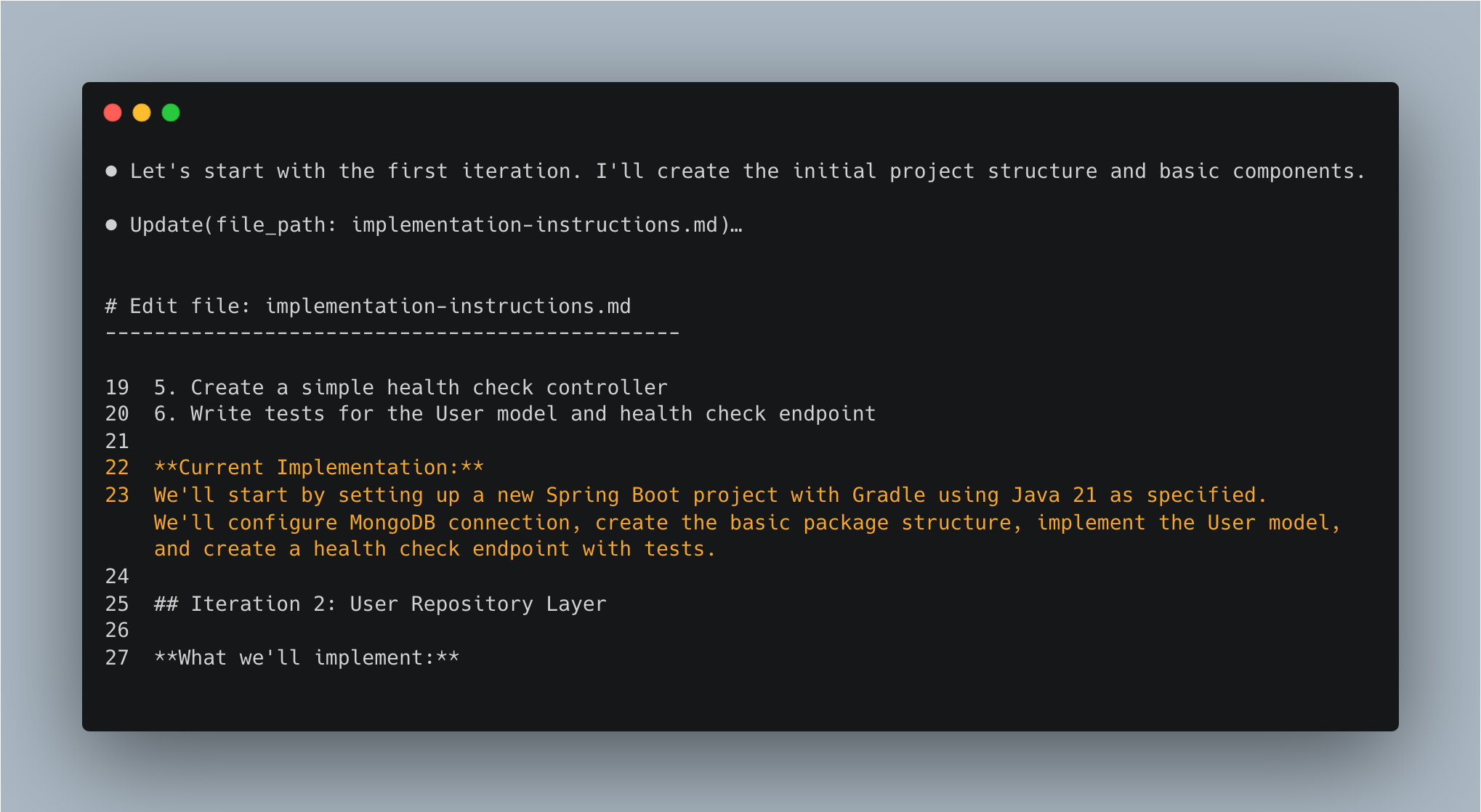
Iteration 1
Claude now spends a bit of time Creating..., after which it has suggested some updates to build.gradle,
bringing in things like spring-boot-starter-web, mongodb and junit.
So far, so good.
Next, it’s suggested updates to application.yml to define config, and then the App.java file which kicks of the main
app runner. I’ve reviewed the accepted
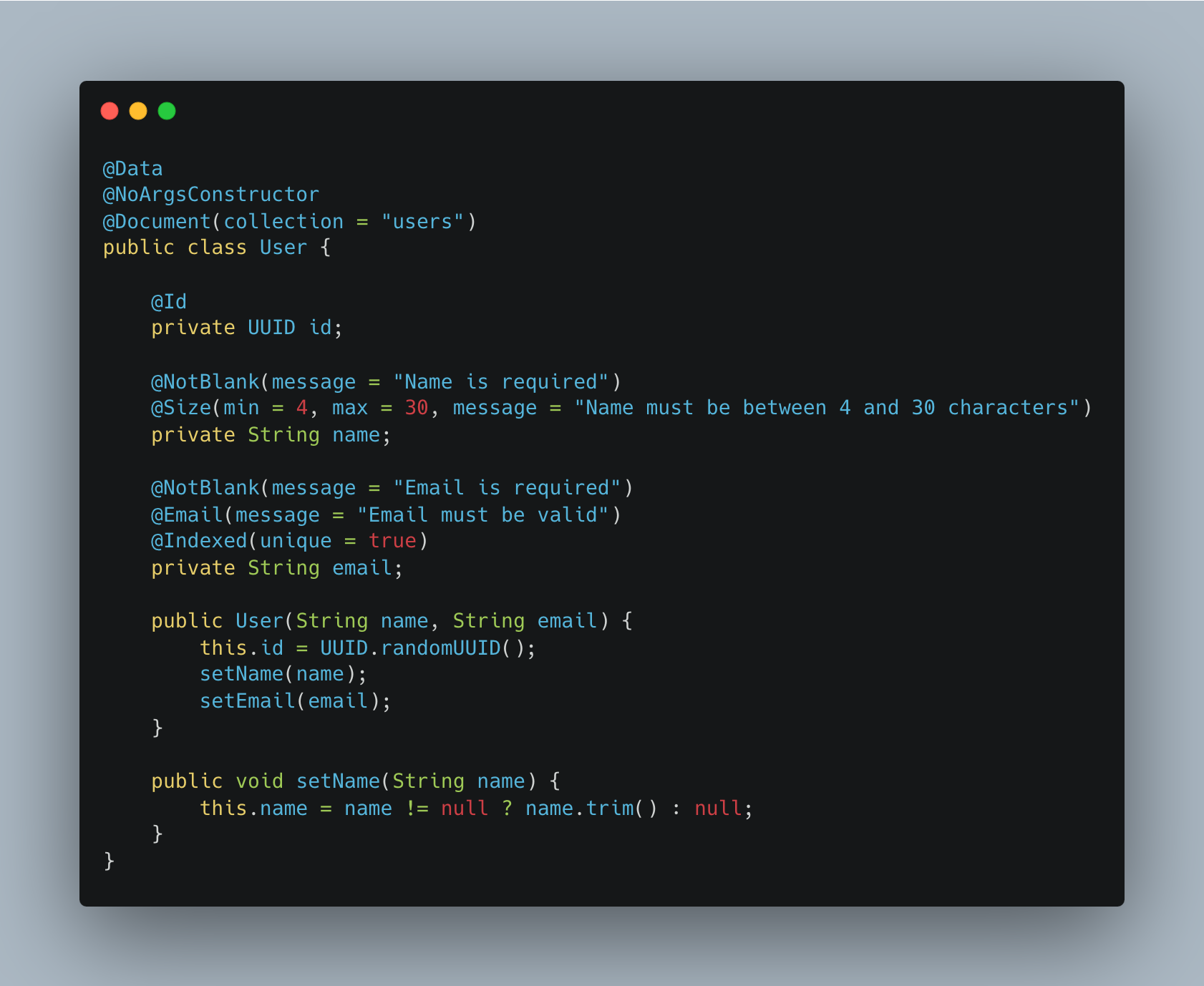
It’s then reached it’s first model definition for User.java. I’ve noticed it’s got explicit getters and setters. I’d
probably prefer to use lombok for this so I’ll not accept the proposed changes and instead ask Claude to do something
differently.
I want you to use lombok here.
I dont really need explicit constructors, getters, setters, to string or hash codes │
Claude has then suggested changes to bring in the lombok dependencies. I’ve reviewed the updated version of User.java
and it looks pretty good.
Next, it has suggested creating bespoke health controllers for the API itself, as well as the Mongo instance. I don’t want to do this as spring’s actuator should do this for me implicitly.
Claude has acknowledged my request and updated its implementation plan accordingly. There are a few more files created for unit tests and shortly after, the first iteration has concluded.
Before it starts Iteration 2, this is a good opportunity to give it a bit of a test.
Testing iteration 1
Once I’ve set up dependencies such as Gradle and MongoDB, I started the app.
The app compiled and ran as normal. I even hit the health check endpoint and confirmed the app was up and running.
Next I ran the tests for the User model. One of the tests for the name/email validation had failed, but I was able quickly fix myself.
Iterations 2-4
Iteration 2
Description: Repository layer for persisting and fetching User objects.
Additional notes: Generally worked pretty well. Its created a standard repository class as well as a custom impl for our additional queries. Automated tests seem to work ok. There are a couple of custom queries that use regex, which I’m not 100% with - I’ll revisit these later.
Cost: $0.30
Iteration 3
Description: Service layer, error handling.
Additional notes: Standard stuff, no issues
Cost: $0.40
Iteration 4
Description: Controller
Additional notes: Creation of controller endpoints for accessing the user data. Some of its suggested endpoints
didn’t follow what I would have considered to be standard REST conventions, e.g. /by-email for getting a user with an
email rather than an id. I instead asked it to tweak the code and got something more suitable.
Cost: $0.40
Testing iterations 2-4 - first e2e test
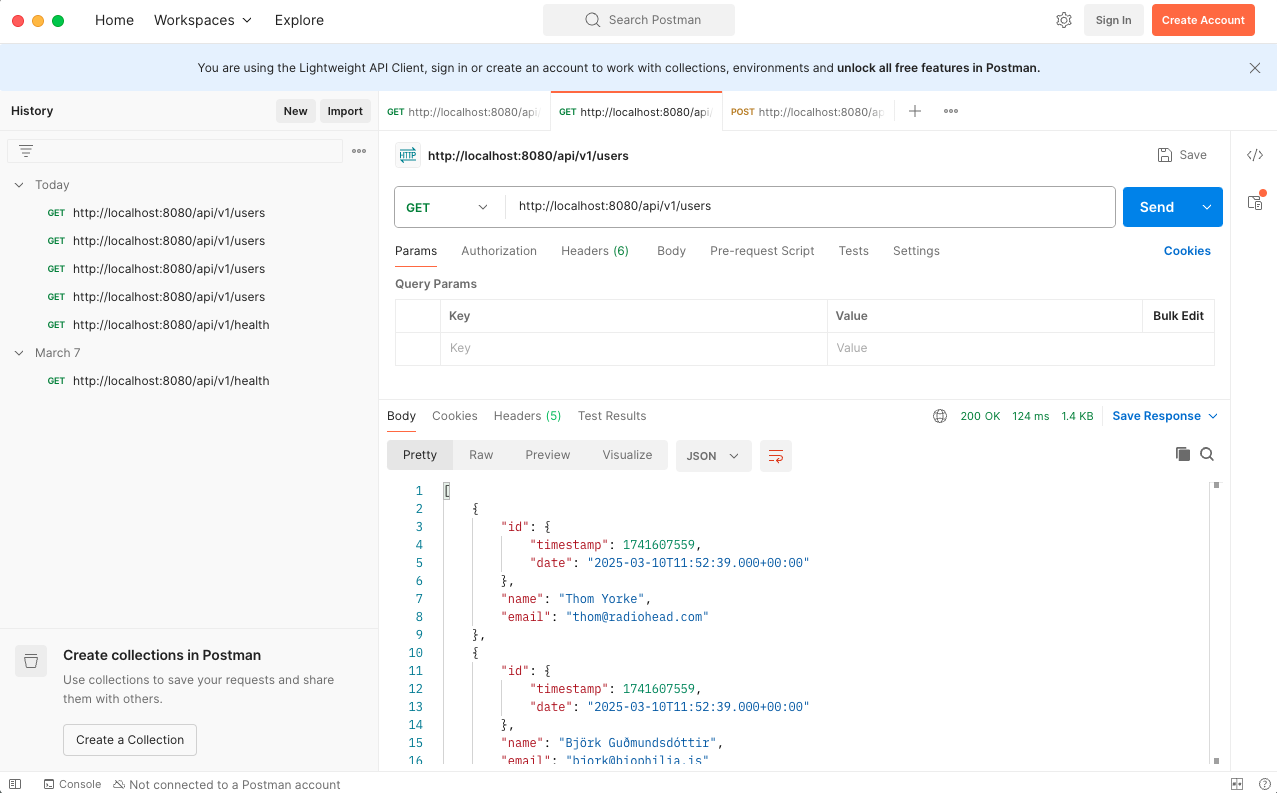
With some sample data loaded into Mongo, I can begin to test the getAllUsers() endpoint. I get a 500 error straight
away and can see from the stack trace its due to a UUID converter. I realised that In my spec, I stipulated that the ID
for mongo objects should be “unique, like a UUID”. In hindsight this was probably not necessary. I should have just
accepted the default of ObjectId.
I’ve asked Claude to go and make these changes. Historically, this would be a tedious find and replace of object types within an IDE. This time, I’ve handed the responsibility over to Claude.
Update: it seemed to miss all the id instances in my test files. I’ve pointed this out to Claude, and it has made the changes.
Update 2: In hindsight this was really expensive. I should stick to the usual find and replace in my IDE next time.
I’ve hit http://localhost:8080/api/v1/users and I’ve got a list of users back. Great!
Iterations 5-7
Iteration 5
Description: Updating users
Additional notes: Endpoint for updating a user with post and patch endpoints. Fairly straightforward with updates to controllers and tests.
Cost: $0.30
Iteration 6
Description: Deleting users
Additional notes: Endpoint for deleting users
Cost: $0.20
Iteration 7
Description: Documentation, logging and final polish
Additional notes: Endpoint for deleting users
Cost: $0.20
Testing iterations 5-7 - final tests
After starting up the application, I test the 4 key functions of the API:
- Get all users
- Get user by id
- Update a user with post/patch
- Delete a user by id
All endpoints and functionality seem to be working as expected.
Conclusion
Running costs
Claude Code will give you an idea of your usage at any time. I started this project with $5 worth of credits.
After Iteration 1, I had used $0.58, which isn’t going to break the bank, but I also hadn’t done a lot yet.
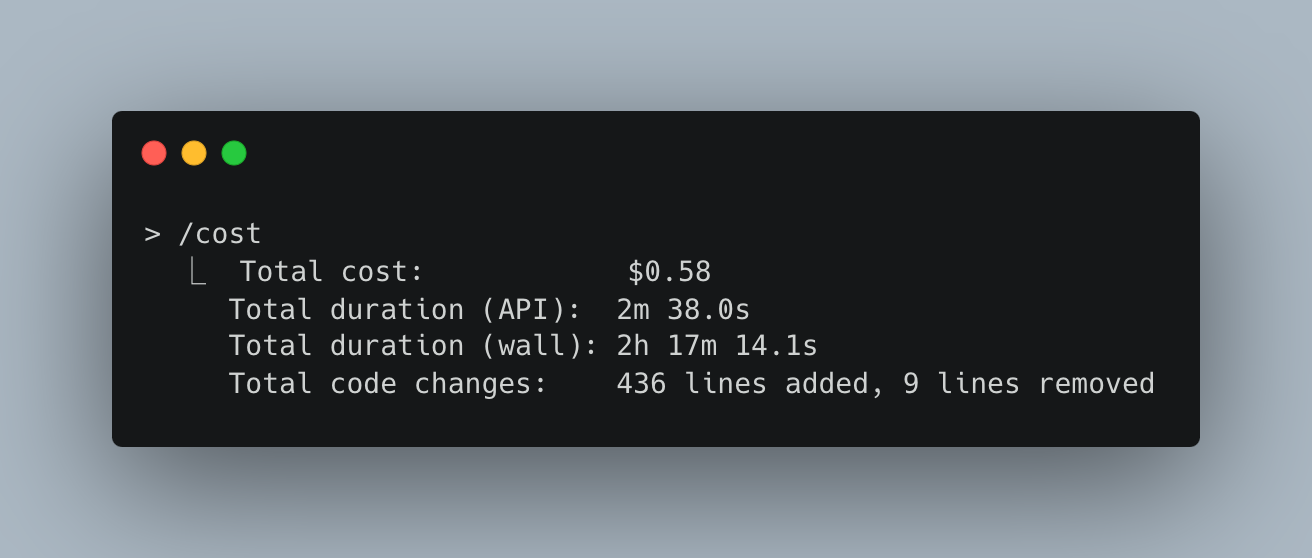
While testing Iteration 4, I then ran out of my initial $5 budget. This seems a bit surprising, as I had only been using between $0.30 and $0.50 per iteration. I had been asking a few questions in between so maybe I did something particularly costly then (I think this was related to the project-wide refactor of the UUID -> ObjectId id type). Unfortunately I had exited my Claude session before I could ask any more questions.
I added another $12, and restarted my build-out.
Once the app was successfully completed. I had consumed in total about $13. Which is really strange because I had asked it to capture the costs of each iteration and this only adds up to ~$ 2-3. I didn’t perform that many ad-hoc requests either. I think this is quite a lot for a sub-1000 loc codebase.
A few other things to note:
- As the code base gets bigger, your costs per transaction are naturally going to increase.
- Things like refactoring across a codebase can be really expensive.
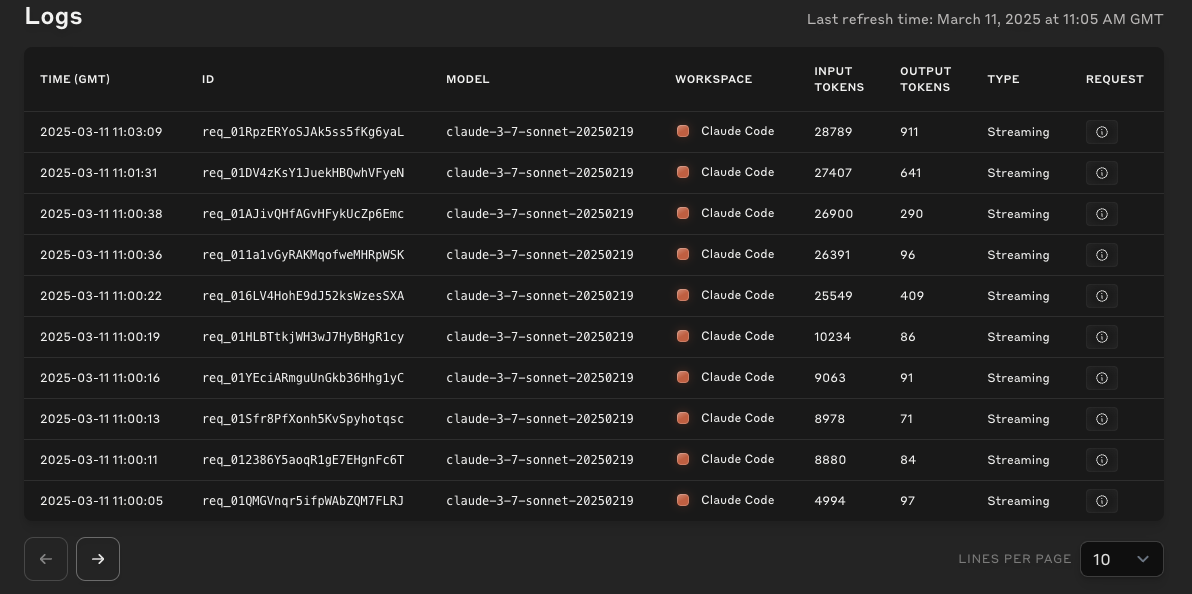
- It can be hard to track exact costings as you go along, but reviewing the logs in your online Anthropic account can
really help. This suggests that my main overhead is data ingress to Claude.
I might want to think of how to use this in a more cost-effective manner. So will do a follow-up post on this in future.
Conclusion
What went well:
- I successfully created a Spring REST API from scratch using Claude Code. The whole process took a couple of hours, scattered over a few days. It was definitely quicker than doing it manually, however this is probably only applicable for low-risk projects. Project source - github.com/m24murray/hands-on-with-claude-spring-mongo
- I appreciate this is still in preview, so keen to see what is next for Claude Code (maybe IDE integration like Copilot).
- Having the spec and implementation changes defined as files that are updated by Claude Code make it really easy to pick up where you left off.
- While the terminal is a tricky interface to work with, if you have the majority of the detail stored in files within code base, it makes it much easier to manage, and the added benefit that this progress can be captured in version control.
Concerns:
- My biggest concern is that things are only going well until they’re not. You can be happily accepting changes until something doesn’t work. Then you find yourself lost and unable to work back your changes.
- Next biggest concern is cost. I had a rather detailed spec file, but it still cost me over $10 for a really small app.
- Sometimes it’ll tell you its editing a file, but you have no understanding why.
- The ability to review proposed file changes only really work if you’re dealing with < 100 lines of code. Anything more and the in-terminal diff becomes too hard to comprehend. In some of these instances, I’ve found myself just accepting the changes, then making a mental note to go and review them in my IDE after.
- It definitely seems to omit implementation of functionality that would use a library, e.g. lombok and actuator. I might include this as a requirement in future spec files.